
Filtering Fake News using Python has never been easier
With the rapid development of information technology, communication has been easier than it has ever been before. This results in fake news becoming more widespread. Everyday people from around the world are more susceptible to irresponsible people writing fake news. That is why technology to verify news is gradually needed. A simple solution to help verify news is to search for the keywords used in the news title, query them in a search engine and review if the given results are similar. This is one of the easiest ways to verify if a news article is fake or not.

For computers to process tasks like these, it will be required to use methods such as natural language processing. Natural Language Processing is a subfield of computer science and artificial intelligence concerned with computers processing natural human language. Using this method we can process these articles to find keywords that reflect the objective of the article. Once the keywords are found we just need to search for articles with similar keywords on the internet. The search results will verify the validity of the article. The main programming language that is going to be used will mainly be Python because Python has a lot of libraries related to natural language processing.
These are the Libraries that are going to be used to develop our fake news classifier.
nltk
beautifulsoup4
selenium>=2.44.0,<3.0.0
requests
unidecode
vcrpy
future
fake-useragent
newspaper3k
sklearn
git+https://github.com/abenassi/Google-Search-API
First, copy these to your own version of requirements.txt in your applications’ root folder. Then to install these libraries, just open up a command line and type these commands in your source folder.
For Windows:
pip install -r requirements.txt
For Linux (install pip3 first):
pip3 install -r requirements.txt
To find similar news articles the function will have two formal parameters. One to receive news parameters either in link or string and another to receive a similarity index. If the received news params is a link then the newspaper3k library will parse and extract the articles’ title, but if the received param is a string then it will be assumed as the articles’ title. Before the text goes through further processing, the text must be normalized so that it would not contain any punctuation or other symbols that might cause noise in the data.
def remove_unnecessary_noise(text_messages):
text_messages = re.sub(r'\\([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])\\([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])\\([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])', ' ', text_messages)
text_messages = re.sub(r'\\([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])\\([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])([a-z]|[A-Z]|[0-9])', ' ', text_messages)
text_messages = re.sub(r'\[[0-9]+\]|\[[a-z]+\]|\[[A-Z]+\]|\\\\|\\r|\\t|\\n|\\', ' ', text_messages)
return text_messages
Normalization will need a new function, the function will have only one formal parameter intended to receive the article titles. All unnecessary noise such as numbers, punctuation, symbols, and trailing white spaces will be removed. Upper case letters will also be lowercased, this is done because punctuation, symbols, and upper case letters are only used to easily interpret languages.
def preproccess_text(text_messages):
# change words to lower case - Hello, HELLO, hello are all the same word
processed = text_messages.lower()
# Remove remove unnecessary noise
processed = re.sub(r'\[[0-9]+\]|\[[a-z]+\]|\[[A-Z]+\]|\\\\|\\r|\\t|\\n|\\', ' ', processed)
# Remove punctuation
processed = re.sub(r'[.,\/#!%\^&\*;\[\]:|+{}=\-\'"_”“`~(’)?]', ' ', processed)
# Replace whitespace between terms with a single space
processed = re.sub(r'\s+', ' ', processed)
# Remove leading and trailing whitespace
processed = re.sub(r'^\s+|\s+?$', '', processed)
return processed
Next, the title will go through tokenization, stopwords removal and stemming. Tokenization is when words in a sentence are separated into arrays equal to the number of words contained in said sentences. For example a sentence ‘I love ice cream’ will be tokenized into an array each containing the words [‘I’, ‘love’, ‘ice’, ‘cream’]. Then all the words that count as stopwords are excluded from the sentence, stopwords are extra words added to make natural languages easier to understand. English stopwords include ‘I’, ‘who’, ‘that’, etc. Next, the title will go through stemming, this is a process that derives words to their original stems, for example, the word playing, played, and plays are all derived from the wordplay.
def news_title_tokenization(message):
stopwords = nltk.corpus.stopwords.words('english')
tokenized_news_title = []
ps = PorterStemmer()
for word in word_tokenize(message):
if word not in stopwords:
tokenized_news_title.append(ps.stem(word))
return tokenized_news_title
If the sentence is normalized and each word is tokenized the next thing to do is to search for the acquired keywords using the Google-Search-API. This API will search the internet for pages that contain these keywords. Each result will go through the process of normalization and tokenization again to help measure the similarities between the two articles titles.
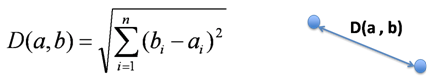
Measuring the similarity will be done using the Euclidian Distance algorithm. The search keywords and the result keywords will be put in an array and the similarities will be measured. Euclidian Distance uses a Pythagorean theorem to measure the distances between two points. The more similar the search and results are the smaller the Euclidian Distance will be. Thus the maximum number of Euclidian Distance has to be set as tolerance of similarity. The smaller the maximum number is, the more specific the comparison will be. A large maximum number will result in generalization. In this case, the similarity index is already defined by the second formal parameter of the find similar articles function.
def find_similar_articles(news, similarity):
news_title_tokenized = ""
if(re.match(r'^https?:\/\/(www\.)?[-a-zA-Z0-9@:%._\+~#=]{2,256}\.[a-z]{2,6}\b([-a-zA-Z0-9@:%_\+.~#?&//=]*)$', news)):
news_article = Article(news)
news_article.download()
news_article.parse()
news_title_tokenized = news_title_tokenization(preproccess_text(news_article.title))
else:
news_title_tokenized = news_title_tokenization(preproccess_text(news))
search_title = ""
for word in news_title_tokenized:
search_title = search_title + word + " "
num_page_searched = 1
search_results = google.search(search_title, num_page_searched)
similar_articles = []
for result in search_results:
similar_article = {}
search_result_title = result.name.split('http')[0].split('...')[0]
search_result_title = remove_unnecessary_noise(search_result_title)
search_result_title = preproccess_text(search_result_title)
search_result_title = news_title_tokenization(search_result_title)
result_string = ""
for w in search_result_title:
result_string = result_string + w + " "
corpus = []
corpus.append(search_title)
corpus.append(result_string)
vectorizer = CountVectorizer()
features = vectorizer.fit_transform(corpus).todense()
for f in features:
dist = euclidean_distances(features[0], f)
if dist < similarity:
similar_article["article_title"] = result.name.split('http')[0].split('...')[0]
similar_article["article_url"] = result.link
similar_articles.append(similar_article)
return similar_articles
If an article is found the program will return a message “Found a similar article!”. When multiple similar article titles are found the program will return a message “Found similar articles!”, but if the program fails to find a similar article the program will return “No similar articles found!” as a message. If there are no similar articles found on the internet, the credibility if the article in question can be assumed false. This is because there are no factors to give an account of the article. Therefore every article that is read on the internet must be taken with a grain of salt because if we do not confirm its’ source there is a possibility that the article we are reading is false.


